
Unstructured data presents many complexities for analysts and researchers, as data, often in the form of texts, has to be analysed for meaningful patterns that inform on relevant events, people, and other data. For spatial information, finding information about places can be difficult, as knowing the context of how places are indicated is critical.
Within the larger field of natural language processing, new methods are being developed that are merging geographic information with basic texts and human language. In particular, methods that employ named entity recognition (NER) have enabled improved methods for automatically finding relevant place names.
Recent developments, particularly with artificial intelligence and machine learning approaches, have now made it easier to automatically detect place names in unstructured texts where data can be parsed to glean important information about a place in discussion.
One new tool developed is GeoTxt, which uses NER techniques and models, where the process is deployed to automatically finding proper names and other nouns, and associating them with given places or objects as needed. Key heuristics and toponym resolution methods are applied where algorithms can learn and determine if information is talking about a particular place.
Supervised machine learning, often deploying statistical and patterned behavioural rules help suggest a likelihood that a given place is in discussion.[1]

Other studies have also confirmed that statistical based supervised learning approaches, similar to GeoTxt, enable easier auto-recognition of spatially-relevant place names.
However, where challenges are evident, they have included developing methods that can better capture natural language change, spelling variation, and different types of language concepts conveyed in text in parsing and determining the location of places within text. In other words, by heavily depending on statistical supervised learning methods, training data that does not fully represent varied but relevant cases are likely to miss identifying relevant places.
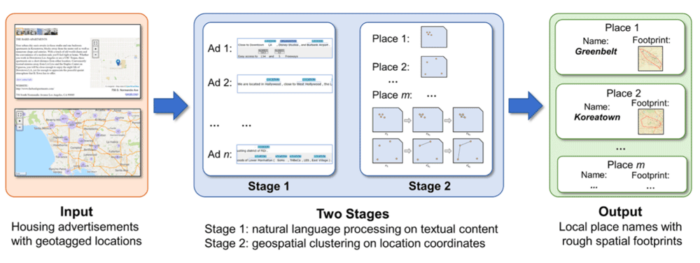
Combining multiple and different data sets with different training procedures could be one way such cases are resolved.[2] Methods have developed gazetteers and models with NER methods that could then be deployed for an analysis. Stronger methods are generally those that combine multiple sets of NER models and gazetteers, combing the strengths of approaches that had learned from previous results.[3]

Other interesting developments include disambiguating textual data referring to the same place. One issue is sometimes multiple texts might be discussing the same place. Disambiguating when texts are discussing the same, nearby, or more distant places could be complicated by the descriptors used.
Matching descriptions and comparing them to each other, however, allows an ambiguity scale to be developed. In other words, comparing contextual data, and not just the place name, determines if an area discussed in one text is likely discussing the same or different place in another text or even within the same text. Spatial relations are created and developed from place descriptions, where they are then compared.[4]
Increasingly, the challenge has been to more accurately define what space means when a given place is indicated. For instance, if a city, such as New York is discussed, within that city the discussion might pertain to a small area, such as a neighborhood, or something relevant for the entire city, such as crime.
The spatial dimension might be defined by the text but not evident simply by comparing different gazetteers. The dimensions of a given discussion, effectively, may need to be extracted or learned, requiring methods that also look at descriptive words to match them with approximate measures of area.
Contexts that define descriptive terms in relation to wider space have to also be investigated extracted and seen if they are relevant for the place in discussion.[5]
In general, NER has become a wider technique used to better locate spatial data within geographic relevant materials. The application of NER has been increasing, but challenges lay ahead. These have included using historical data, where language itself has changed and often the spelling or naming of a place. Additionally, defining exactly what space is discussed is not an easy problem, particularly when descriptions have to be investigated to determine the dimensions of a given space of discussion.
References
[1] For more on how GeoTXT is able to determine given toponyms and find meaningful patterns within unstructured text, see: Karimzadeh, M., Pezanowski, S., MacEachren, A. M., & Wallgrün, J. O. (2019). GeoTxt: A scalable geoparsing system for unstructured text geolocation. Transactions in GIS, 23(1), 118–136. https://doi.org/10.1111/tgis.12510.
[2] For more on problems faced in auto-detecting place names using named entity recognition techniques, see: Won, M., Murrieta-Flores, P., & Martins, B. (2018). Ensemble Named Entity Recognition (NER): Evaluating NER Tools in the Identification of Place Names in Historical Corpora. Frontiers in Digital Humanities, 5. https://doi.org/10.3389/fdigh.2018.00002.
[3] Method combine gazetteers and using different NER models could be investigated and are discussed here: Hu, Y., Mao, H., & McKenzie, G. (2019). A natural language processing and geospatial clustering framework for harvesting local place names from geotagged housing advertisements. International Journal of Geographical Information Science, 33(4), 714–738. https://doi.org/10.1080/13658816.2018.1458986
[4] For more on comparing similar descriptions of places and named entities, see: Kim, J., Vasardani, M., & Winter, S. (2017). Similarity matching for integrating spatial information extracted from place descriptions. International Journal of Geographical Information Science, 31(1), 56–80. https://doi.org/10.1080/13658816.2016.1188930.
[5] For more on issues raised with NER and context of spatial dimensions, see: Paterson, L. L., & Gregory, I. N. (2019). Geographical Information Systems and Textual Sources. In L. L. Paterson & I. N. Gregory, Representations of Poverty and Place(pp. 41–60). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-93503-4_3