
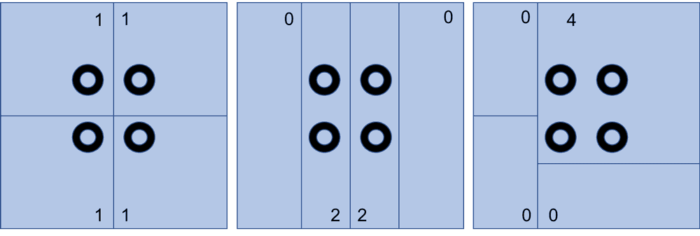
The modifiable areal unit problem (MAUP) is a statistical biasing effect when samples in a given area are used to represent information such as density in a given area. The area defined by an analyst is often arbitrary, thus measurement such as density could be deceptive because that density measure could have widely different results based on shape and scale chosen for analysis.
Who first addressed the modifiable areal unit problem?
The Modifiable Areal Unit Problem (MAUP) was first systematically addressed by geographer Stan Openshaw in 1984, who wrote “the areal units (zonal objects) used in many geographical studies are arbitrary, modifiable, and subject to the whims and fancies of whoever is doing, or did, the aggregating.”Openshaw noted that the way data is aggregated into different spatial units, like districts or neighborhoods, can significantly affect the conclusions drawn from that data. Openshaw’s work brought attention to the fact that these variations are not mere anomalies, but are deeply rooted in the very structure of spatial data analysis. His research emphasized that analysts must be cautious when interpreting spatial data, as the choice of areal units (the size and shape of the regions being studied) could inadvertently bias results.
What are the effects of the modifiable areal unit problem?
The effects of MAUP have been documented in many studies. As an example, in landscape ecology, MAUP effects on scale, that is aggregating to larger spatial units, and rezoning, or moving the boundaries of an area measured, both have significant results in result evaluation. Areas under ecological stress, for instance, could be less severe or underestimate in their severity. This was demonstrated using Normalized Difference Vegetation Index (NDVI) values, for instance.[1]
The issue of MAUP is evident in fields such as health spatial statistics, where aggregating disease or other health issues are commonly done in order to determine spatial factors that relate to given disease. One way to check the robustness of results when aggregation is done and analyses such as spatial autocorrelation is applied is to change the scale of the aggregation then measure results to check for robustness or variation of outputs. If results are significantly different, then that likely means the scale needs to be reevaluated or reapplied so that more consistent results are achieved. An across-scale relationship evaluation between variables could help to avoid erroneous conclusions or at least provide guidance in making selection for appropriate aggregation scales.[2]

Similarly, Bayesian spatial models and sampling procedures are used to estimate appropriate scales of aggregation by varying the scale and boundaries in which aggregation occurs. This helps to determine where values for autocorrelation among tested variables are most robust or provide the most stable outputs. This was done in an example looking at population density, median household income and traffic accidents. Randomly sampling and trying different parameter settings also provides understanding of range variation in results.[3]
Another method to counteract this effect is simply make the evaluated variables as fine scale as possible. Points, for instance, that are measured against other points help to remove or diminish MAUP. This was done in relation to assessing sires for tornados in Oklahoma.
The coverage area, that is which areas are able to have sirens reaching them, was assessed using points conducted at the finest scale possible. The downside is this could require more memory, as it avoids aggregation, but where memory is less of an issue this could be a robust application if data can be at a relatively fine scale.[4]

Software has now been developed to address the issue of MAUP to make it easier for analysts to choose the right spatial scale for evaluation. Tools that apply random sampling, probing techniques, and semi-automated tests that inform on where sensitivities are minimized in results and the best scales to measure have been developed. Tools such as the Urban Growth Decision Support System have developed such applications.[5]
For most GIS practitioners, MAUP is something to be aware of when different analytical techniques are applied. While many analyses often do not sufficiently address this problem, there are relatively easy ways in which can be addressed. Tools do exist to help researchers find the best or more optimal scales in which to aggregate or sample their data, including sensitivity analyses and robustness of outputs should be checked using statistical procedures such as Bayesian variation of zone scale and area coverage.
References
Openshaw, S. (1984). Ecological fallacies and the analysis of areal census data. Environment and planning A, 16(1), 17-31. https://doi.org/10.1068/a160017
[1] For more on problems caused by MAUP in landscape ecolgy, see: Jelinski, D. E., & Wu, J. (1996). The modifiable areal unit problem and implications for landscape ecology. Landscape Ecology, 11(3), 129–140. https://doi.org/10.1007/BF02447512
[2] For more information on ways to counteract MAUP in health spatial statistics and potentially other spatial analyses, see: Nelson, J. K., & Brewer, C. A. (2017). Evaluating data stability in aggregation structures across spatial scales: revisiting the modifiable areal unit problem. Cartography and Geographic Information Science, 44(1), 35–50. https://doi.org/10.1080/15230406.2015.1093431.
[3] For more on Bayesian tehcniques for MAUP assessment, see: Xu, P., Huang, H., Dong, N., & Abdel-Aty, M. (2014). Sensitivity analysis in the context of regional safety modeling: Identifying and assessing the modifiable areal unit problem. Accident Analysis & Prevention, 70, 110–120. https://doi.org/10.1016/j.aap.2014.02.012.
[4] For more on using points and fine scale analyses for avoiding MAUP, see: Mathews, A. J., & Ellis, E. A. (2016). An evaluation of tornado siren coverage in Stillwater, Oklahoma: Optimal GIS methods for a spatially explicit interpretation. Applied Geography, 68, 28–36. https://doi.org/10.1016/j.apgeog.2016.01.007.
[5] For more on MAUP alleviaton methods and user tools to help with this, see: Butkiewicz, T., Meentemeyer, R. K., Shoemaker, D. A., Chang, R., Wartell, Z., & Ribarsky, W. (2010). Alleviating the Modifiable Areal Unit Problem within Probe-Based Geospatial Analyses. Computer Graphics Forum, 29(3), 923–932. https://doi.org/10.1111/j.1467-8659.2009.01707.x.
Random versus MAUP scenario: Swift, A., Liu, L., & Uber, J. (2008). Reducing MAUP bias of correlation statistics between water quality and GI illness. Computers, Environment and Urban Systems, 32(2), 134-148.
This article was first published on one 14, 2018 and has since been updated.