
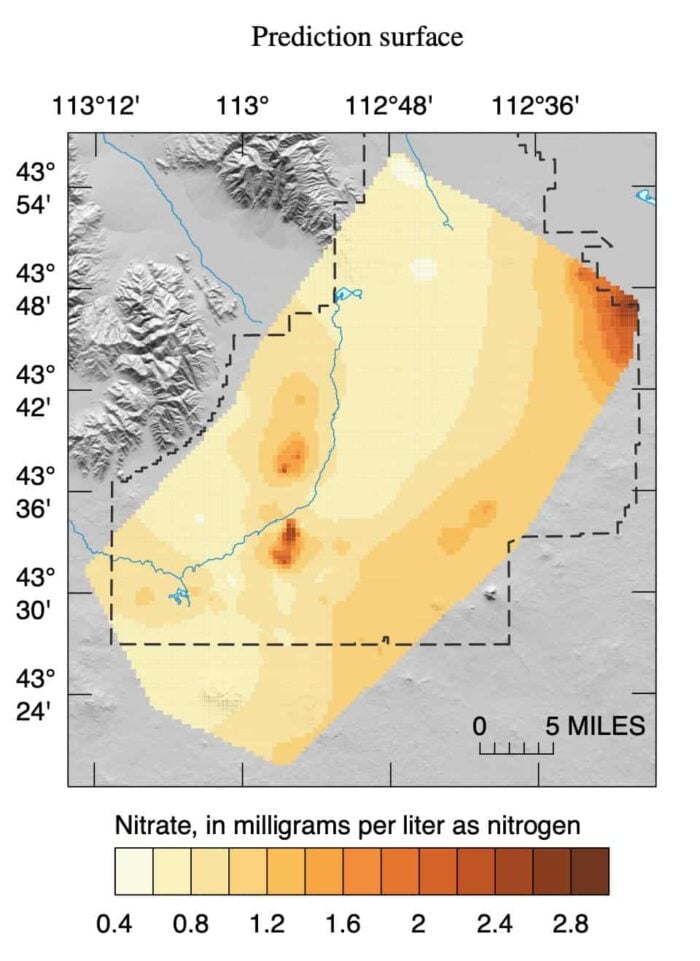
The strength of different spatial interpolation methods is relevant to improve spatially continuous results, such as mapping data on surfaces or sampling from different land use areas.
These geospatial techniques attempt to determine likely values, often raster data, in a given space. Among various methods, ordinary kriging (OK), inverse distance weighting (IDW), local polynomial interpolation (LPI), and radial basis function (RBF) have proven to be among the most common methods.
Spatial interpolation methods collect known values from a dataset of sample points in order to estimate, or best predict, the value of an unknown point or raster cell.

Evaluating Spatial Interpolation Models
Papers have evaluated the strength of these common techniques. In general, results for interpolation are often not consistent, as some methods may show greater or better results for different types of cases.
At times, ordinary kriging has appeared among the strongest in producing high coefficient of determination results that show strong fit in estimates or predictions to empirical data.[1] Nevertheless, this is often case specific and seeding of data may show other methods to be more accurate, where variability in an evaluated surface has a strong effect on results.[2]

Other work has shown that the various interpolation methods could all be useful in areas related to assessing water quality.[3] In general, methods for interpolation could be deterministic or stochastic. In deterministic models, they may be over fitted to given test data, while in stochastic models data may not properly address given areas where there are data deficiencies.
Accommodating Diverse Data Types
More varied types of data, including such data that include time-specific and spatial information, have also incorporated interpolation methods that estimate for each relevant period of analysis.
In particular, as research begins to incorporate digital data, such as mobile phone data, as means to approximate traffic, human movement patterns, or even simply where people aggregate for understanding daily routines, new methods are needed to accommodate not only spatiotemporal change but also factors such as cultural preferences, events, or other factors that act as weights into any interpolation.
Dasymetric interpolation
One method created is dasymetric interpolation.[4] In this case, the data surface is represented by the density of points (e.g., mobile phones) in an area, where the map produced from the interpolation is similar to choropleth maps that are based on stepped statistics.
Cartographers have liked this method as it allows the interpolation to incorporate geography and other factors that allow abrupt or smoother changes to be estimated for a given surface.
Surface Anomalies
Other problems of interpolation address very abrupt changes in distribution of contents on given surfaces. For example, geochemical change often are tightly clustered and large variation could occur between nearby places.
Methods such applying C-A (concentration area) fractal models have been developed to estimate where those changes might be and create distribution maps of different geochemicals by determining different origins of the chemicals.[5]
The basic idea is that in a given space, each cell has a threshold of concentration for given anomalies. Cells that exceed this threshold then develop characteristics where they abruptly change and develop anomalies such as in geochemical signature. These factors can include multiple elements and their combination could affect the specific change to a given anomaly.

Overall, interpolation methods have proven vital from areas such as public health to interpreting weather patterns. Complexities in the nature of data ensure that many different methods have to be developed that best address the nature and change in data for given estimated surfaces over space and time.
References
[1] For more on the comparison of different interpolation methods and their utility, see: Buhina, Gouri S., Shit, P. V., Maiti, R. 2016. Comparison of GIS-based interpolation methods for spatial distribution of soil organic carbon (SOC). Journal of the Saudi Society of Agricultural Science. doi: 10.1016/j.jssas.2016.02.001.
[2] For more on varied results of effectiveness in interpolation methods, see: Li, J. and Heap, A. D. 2014. Spatial interpolation methods applied in the environmental sciences: A review. Environmental Modelling and Software 53: 173-189.
[3] For more on the use of interpolation in water quality, see: Arslan, H., and Turan, N. A. 2015. Estimation of spatial distribution of heavy metals in groundwater using interpolation methods and multivariate statistical techniques; its suitability for drinking and irrigation purposes in the Middle Black Sea Region of Turkey. Environmental Monitoring and Assessment 187(8): 4725. doi: 10.1007/s10661-015-4725-x.
[4] For more on dasymetric interpolation, see: Järv, O., Tenkanen, H., and Toivonen, T. 2017. Enhancing spatial accuracy of mobile phone data using multi-temporal dasymetric interpolation. International Journal of Geographical Information Science. doi: 10.1080/13658816.2017.1287369.
[5] For more on C-A fractal models, see: Hoang, A.H., and Nguyen, T. T. 2016. Identification of spatial distribution of geochemical anomalies based on GIS and C-A fractal model – A case study of Jiurui copper mining area. Journal of Geosciences and Geomatics 4(2): 36-41.
This article was originally written on June 6, 2017 and has since been updated.